|
| void | calculate_projected_gradient (const size_t _corePosition) |
| | : Calculates the component at _corePosition of the projected gradient from the residual, i.e. E(A^T(b-Ax)). More...
|
| |
| void | calculate_residual (const size_t _corePosition) |
| | (Re-)Calculates the current residual, i.e. Ax-b. More...
|
| |
| std::vector< value_t > | calculate_slicewise_norm_A_projGrad (const size_t _corePosition) |
| | : Calculates ||P_n (A(E(A^T(b-Ax)))))|| = ||P_n (A(E(A^T(residual)))))|| = ||P_n (A(E(gradient)))|| for each n, where P_n sets all entries equals zero except where the index at _corePosition is equals n. In case of RankOneMeasurments, the calculation is not slicewise (only n=0 is set). More...
|
| |
| void | construct_stacks (std::unique_ptr< xerus::Tensor[] > &_stackSaveSlot, std::vector< std::vector< size_t > > &_updates, const std::unique_ptr< Tensor *[]> &_stackMem, const bool _forward) |
| | Constructes either the forward or backward stack. That is, it determines the groups of partially equale measurments. Therby stetting (forward/backward)- Updates, StackMem and SaveSlot. More...
|
| |
| std::vector< Tensor > | get_fixed_components (const Tensor &_component) |
| | Returns a vector of tensors containing the slices of _component where the second dimension is fixed. More...
|
| |
| template<class PositionType > |
| void | perform_dyadic_product (const size_t _localLeftRank, const size_t _localRightRank, const value_t *const _leftPtr, const value_t *const _rightPtr, value_t *const _deltaPtr, const value_t _residual, const PositionType &_position, value_t *const _scratchSpace) |
| | Calculates one internal step of calculate_projected_gradient. In particular the dyadic product of the leftStack, the rightStack and the position vector. More...
|
| |
| template<> |
| void | perform_dyadic_product (const size_t _localLeftRank, const size_t _localRightRank, const value_t *const _leftPtr, const value_t *const _rightPtr, value_t *const _deltaPtr, const value_t _residual, const size_t &_position, value_t *const) |
| |
| template<> |
| void | perform_dyadic_product (const size_t _localLeftRank, const size_t _localRightRank, const value_t *const _leftPtr, const value_t *const _rightPtr, value_t *const _deltaPtr, const value_t _residual, const Tensor &_position, value_t *const _scratchSpace) |
| |
| void | resize_stack_tensors () |
| | Resizes the unqiue stack tensors to correspond to the current ranks of x. More...
|
| |
| void | solve_with_current_ranks () |
| | Basically the complete algorithm, trying to reconstruct x using its current ranks. More...
|
| |
| void | update_backward_stack (const size_t _corePosition, const Tensor &_currentComponent) |
| | For each measurment sets the backwardStack at the given _corePosition to the contraction between the backwardStack at the previous corePosition (i.e. +1) and the given component contracted with the component of the measurment operator. For _corePosition == corePosition and _currentComponent == x.components(corePosition) this really updates the stack, otherwise it uses the stack as scratch space. More...
|
| |
| template<> |
| void | update_backward_stack (const size_t _corePosition, const Tensor &_currentComponent) |
| |
| template<> |
| void | update_backward_stack (const size_t _corePosition, const Tensor &_currentComponent) |
| |
| void | update_forward_stack (const size_t _corePosition, const Tensor &_currentComponent) |
| | For each measurment sets the forwardStack at the given _corePosition to the contraction between the forwardStack at the previous corePosition (i.e. -1) and the given component contracted with the component of the measurment operator. For _corePosition == corePosition and _currentComponent == x.components(corePosition) this really updates the stack, otherwise it uses the stack as scratch space. More...
|
| |
| template<> |
| void | update_forward_stack (const size_t _corePosition, const Tensor &_currentComponent) |
| |
| template<> |
| void | update_forward_stack (const size_t _corePosition, const Tensor &_currentComponent) |
| |
| void | update_x (const std::vector< value_t > &_normAProjGrad, const size_t _corePosition) |
| | Updates the current solution x. For SinglePointMeasurments the is done for each slice speratly, for RankOneMeasurments there is only one combined update. More...
|
| |
| template<> |
| void | update_x (const std::vector< value_t > &_normAProjGrad, const size_t _corePosition) |
| |
| template<> |
| void | update_x (const std::vector< value_t > &_normAProjGrad, const size_t _corePosition) |
| |
|
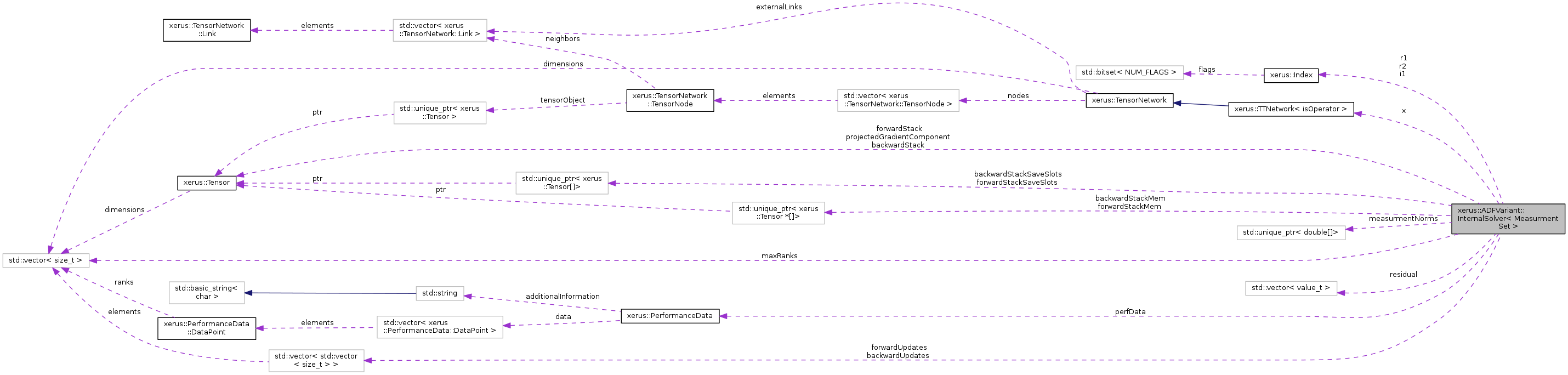
| Tensor *const *const | backwardStack |
| | Array [numMeasurments][degree]. For positions larger than the current corePosition and for each measurment, this array contains the pre-computed contraction of the last _ component tensors and the last _ components of the measurment operator. These tensors are deduplicated in the sense that for each unqiue part of the position only one tensor is actually stored, which is why the is an array of pointers. The Tensors at the current corePosition are used as scratch space. For convinience the underlying array (forwardStackMem) is larger, wherefore also the positions -1 and degree are allow, all poining to a {1} tensor containing 1 as only entry. Note that position zero must not be used. More...
|
| |
| std::unique_ptr< Tensor *[]> | backwardStackMem |
| | Ownership holder for a (degree+2)*numMeasurments array of Tensor pointers. (Not used directly) More...
|
| |
| std::unique_ptr< Tensor[]> | backwardStackSaveSlots |
| | Ownership holder for the unqiue Tensors referenced in backwardStack. More...
|
| |
| std::vector< std::vector< size_t > > | backwardUpdates |
| | Vector containing for each corePosition a vector of the smallest ids of each group of unique backwardStack entries. More...
|
| |
| const size_t | degree |
| | Degree of the solution. More...
|
| |
| Tensor *const *const | forwardStack |
| | Array [numMeasurments][degree]. For positions smaller than the current corePosition and for each measurment, this array contains the pre-computed contraction of the first _ component tensors and the first _ components of the measurment operator. These tensors are deduplicated in the sense that for each unqiue part of the position only one tensor is actually stored, which is why the is an array of pointers. The Tensors at the current corePosition are used as scatch space. For convinience the underlying array (forwardStackMem) is larger, wherefore also the positions -1 and degree are allow, all poining to a {1} tensor containing 1 as only entry. Note that position degree-1 must not be used. More...
|
| |
| std::unique_ptr< Tensor *[]> | forwardStackMem |
| | Ownership holder for a (degree+2)*numMeasurments array of Tensor pointers. (Not used directly) More...
|
| |
| std::unique_ptr< Tensor[]> | forwardStackSaveSlots |
| | Ownership holder for the unqiue Tensors referenced in forwardStack. More...
|
| |
| std::vector< std::vector< size_t > > | forwardUpdates |
| | Vector containing for each corePosition a vector of the smallest ids of each group of unique forwardStack entries. More...
|
| |
| const Index | i1 |
| |
| size_t | iteration |
| | The current iteration. More...
|
| |
| double | lastResidualNorm |
| | The residual norm of the last iteration. More...
|
| |
| const size_t | maxIterations |
| | Maximal allowed number of iterations (one iteration = one sweep) More...
|
| |
| const std::vector< size_t > | maxRanks |
| | Maximally allowed ranks. More...
|
| |
| std::unique_ptr< double[]> | measurmentNorms |
| | : Norm of each rank one measurment operator More...
|
| |
| const MeasurmentSet & | measurments |
| | Reference to the measurment set (external ownership) More...
|
| |
| const double | minimalResidualNormDecrease |
| | Minimal relative decrease of the residual norm ( (oldRes-newRes)/oldRes ) until either the ranks are increased (if allowed) or the algorithm stops. More...
|
| |
| const value_t | normMeasuredValues |
| | The two norm of the measured values. More...
|
| |
| const size_t | numMeasurments |
| | Number of measurments (i.e. measurments.size()) More...
|
| |
| PerformanceData & | perfData |
| | : Reference to the performanceData object (external ownership) More...
|
| |
| Tensor | projectedGradientComponent |
| | The current projected Gradient component. That is E(A^T(Ax-b)) More...
|
| |
| const Index | r1 |
| | Indices for all internal functions. More...
|
| |
| const Index | r2 |
| |
| std::vector< value_t > | residual |
| | The current residual, saved as vector (instead of a order one tensor). More...
|
| |
| double | residualNorm |
| | Current residual norm. Updated at the beginning of each iteration. More...
|
| |
| const double | targetResidualNorm |
| | The target residual norm at which the algorithm shall stop. More...
|
| |
| TTTensor & | x |
| | Reference to the current solution (external ownership) More...
|
| |
template<class MeasurmentSet>
class xerus::ADFVariant::InternalSolver< MeasurmentSet >
Definition at line 43 of file adf.h.